在現代社會,從解鎖手機到機場安檢,從社交軟件到安防監控,面部識別技術正日益滲透到我們的日常生活之中。這項看似神奇的“識人”能力,其背后是計算機網絡技術與人工智能(AI)深度結合的結晶。人工智能究竟是如何通過計算機網絡技術“認識”并識別我們每一張獨特的面孔呢?
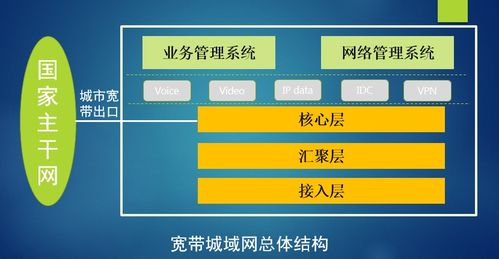
一、數據采集與傳輸:識別的起點
一切始于圖像。當我們面對攝像頭時,網絡攝像頭或高清攝像機捕捉到我們的面部圖像或視頻流。這些原始的圖像數據(由像素點陣構成)通過計算機網絡(有線或無線網絡)被實時傳輸到處理中心。這個過程依賴于高速、穩定的網絡協議(如TCP/IP)和足夠的帶寬,以確保圖像數據的完整性和實時性,為后續分析提供高質量的“原材料”。
二、云計算與分布式處理:大腦的延伸
海量的圖像數據若僅靠本地設備處理,將面臨算力和存儲的瓶頸。因此,現代面部識別系統通常依托于強大的云計算平臺。通過網絡,數據被發送到遠程數據中心。在這里,成千上萬的服務器(構成計算集群)通過計算機網絡協同工作,進行分布式并行計算。這種架構極大地提升了處理速度,使得系統能夠同時處理來自全球數百萬個攝像頭的請求,實現了“大腦”的云端化與無限擴展。
三、核心算法與模型:識別的智慧
這是AI“認識”你的核心環節,其運行嚴重依賴網絡化的計算資源。
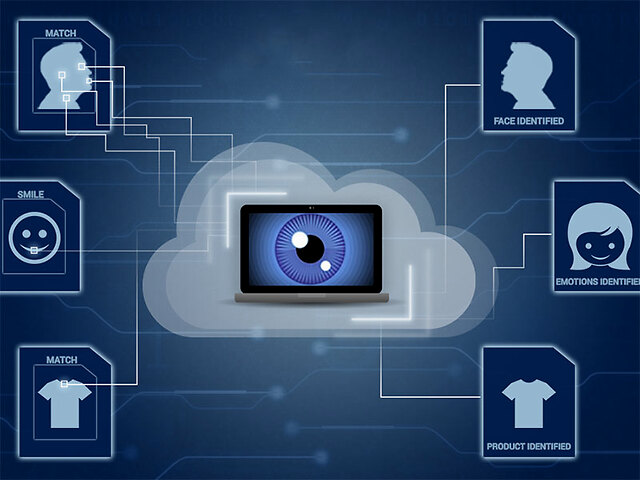
- 人臉檢測:系統利用已訓練好的深度學習模型(如基于卷積神經網絡CNN的算法),從圖像中精準定位人臉區域,將其與背景分離。這些復雜的模型通常存儲在云端,并通過網絡被調用。
- 特征提取:這是最關鍵的一步。AI模型(例如DeepFace、FaceNet等)會對對齊后的人臉進行深度分析,將其轉化為一串獨一無二的數字代碼,稱為“特征向量”或“面部指紋”。這個過程不是測量眼睛、鼻子的大小,而是通過多層神經網絡抽象出人臉的深層、本質特征。訓練這些模型所需的龐大數據集(數以億計標注的人臉圖片)正是通過網絡在全球范圍內收集和分發的。
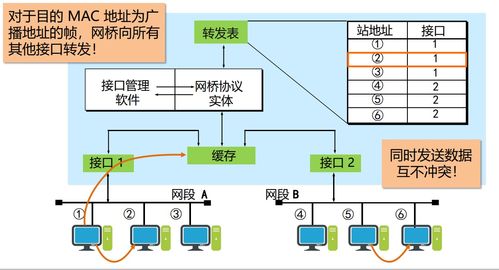
- 特征比對與識別:生成的特征向量會被迅速發送至后臺數據庫進行比對。數據庫可能分布在不同地理位置的服務器上,通過網絡進行高速查詢和匹配。系統計算該向量與庫中已有向量之間的相似度(如余弦相似度),若超過設定閾值,則“認識”了你,完成身份驗證或識別。
四、網絡安全的雙刃劍
計算機網絡技術賦予了面部識別強大能力,也帶來了安全與隱私挑戰。
- 數據安全:人臉特征作為敏感生物信息,在網絡傳輸和存儲過程中必須被加密(如使用SSL/TLS協議),防止被竊取或篡改。
- 隱私倫理:網絡化的系統使得人臉數據可能被遠程集中訪問和濫用,因此需要健全的法律法規與網絡數據治理框架來規范其收集和使用。
- 對抗攻擊:黑客可能通過網絡向系統注入干擾數據(對抗樣本),欺騙AI做出錯誤識別。這要求系統具備持續的網絡防御和模型更新能力。
五、邊緣計算的興起:網絡架構的進化
為了降低網絡延遲、提升實時性并減少云端傳輸壓力,一種新的網絡計算范式——邊緣計算正被應用于面部識別。部分AI處理任務(如初步的人臉檢測)被下放到網絡邊緣的設備本身(如智能攝像頭、手機),只將關鍵特征或必要信息回傳云端。這形成了“云-邊-端”協同的高效網絡架構,使識別更快、更隱私、更可靠。
###
總而言之,人工智能之所以能“認識”我們,絕非單一技術的功勞。它是一個由計算機網絡技術緊密編織而成的生態系統:從前端的數據捕獲與網絡傳輸,到云端的分布式計算與模型服務,再到后臺的網絡化數據庫比對與安全通信。每一次快速、準確的面部識別背后,都是一場跨越網絡的、靜默而高效的數據與智能的協同芭蕾。隨著5G/6G網絡、物聯網及更先進AI算法的發展,這張由技術和網絡構成的“識別之網”將變得更加精準、高效,同時也對我們的技術治理智慧提出更高要求。